“2-car acc @ State & Lake, both drivers injred”
That short, hastily typed text message or tweet contains a lot of information that police, emergency responders, news organizations and drivers could use. A human observer could quickly identify that it refers to an auto accident, a medical emergency, and a street intersection in Chicago.
But without prior experiences and lots of human input, a computer would likely have a hard time recognizing that State and Lake are streets in Chicago, that “acc” is short for accident, or that “injred” is a typo for “injured.”

The non-profit organization Ushahidi was created by a team of developers so that text messages from eyewitnesses on the ground could be quickly mapped and shared with aid agencies, government authorities and journalists.
Since its first use during the violent period after the disputed 2007 Kenyan elections, the organization’s crowd-sourced mapping platform has been shared with human rights volunteers around the world.
Ushahidi’s tool is simple but powerful: it maps reports and lets you filter them by category – “voting issues” or “polling station issues,” in the election monitoring context.
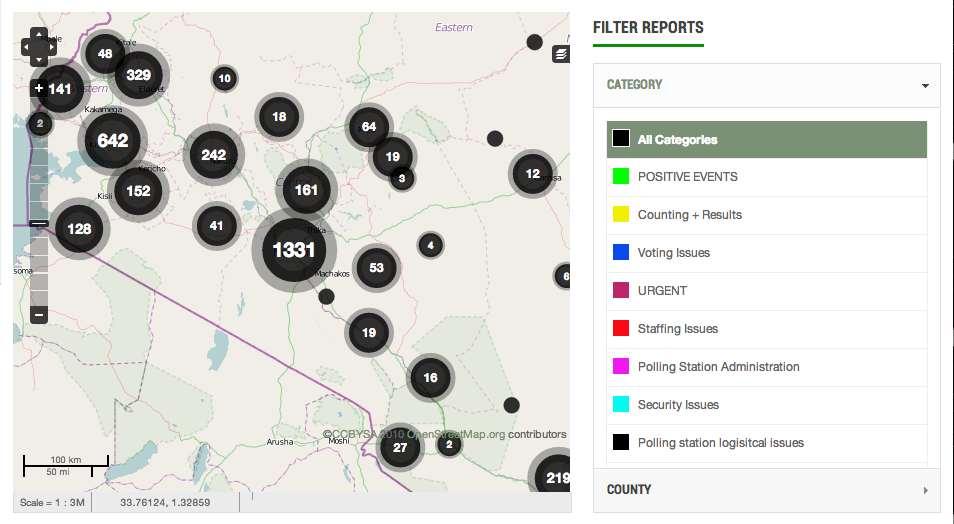
But while Ushahidi harnesses technology to rapidly spread information about what’s happening in the streets, it still runs largely on human power. Currently, during a political crisis, natural disaster, or environmental emergency, volunteers must manually review each SMS, tweet or web report from the field before it can be mapped.
The text that comes in is unorganized, filled with abbreviations and typos and could be in a variety of different languages. Volunteers must manually sort through each message to detect language its written in, extract the report’s location so it can be mapped, tag it with a relevant category, and possibly delete the report if its redundant.
In partnering with Ushahidi, fellows Kayla Jacobs, Nathan Leiby and Kwang-Sung Jun hope to make that review process easier, faster, and more accurate with machine learning and natural language processing techniques.
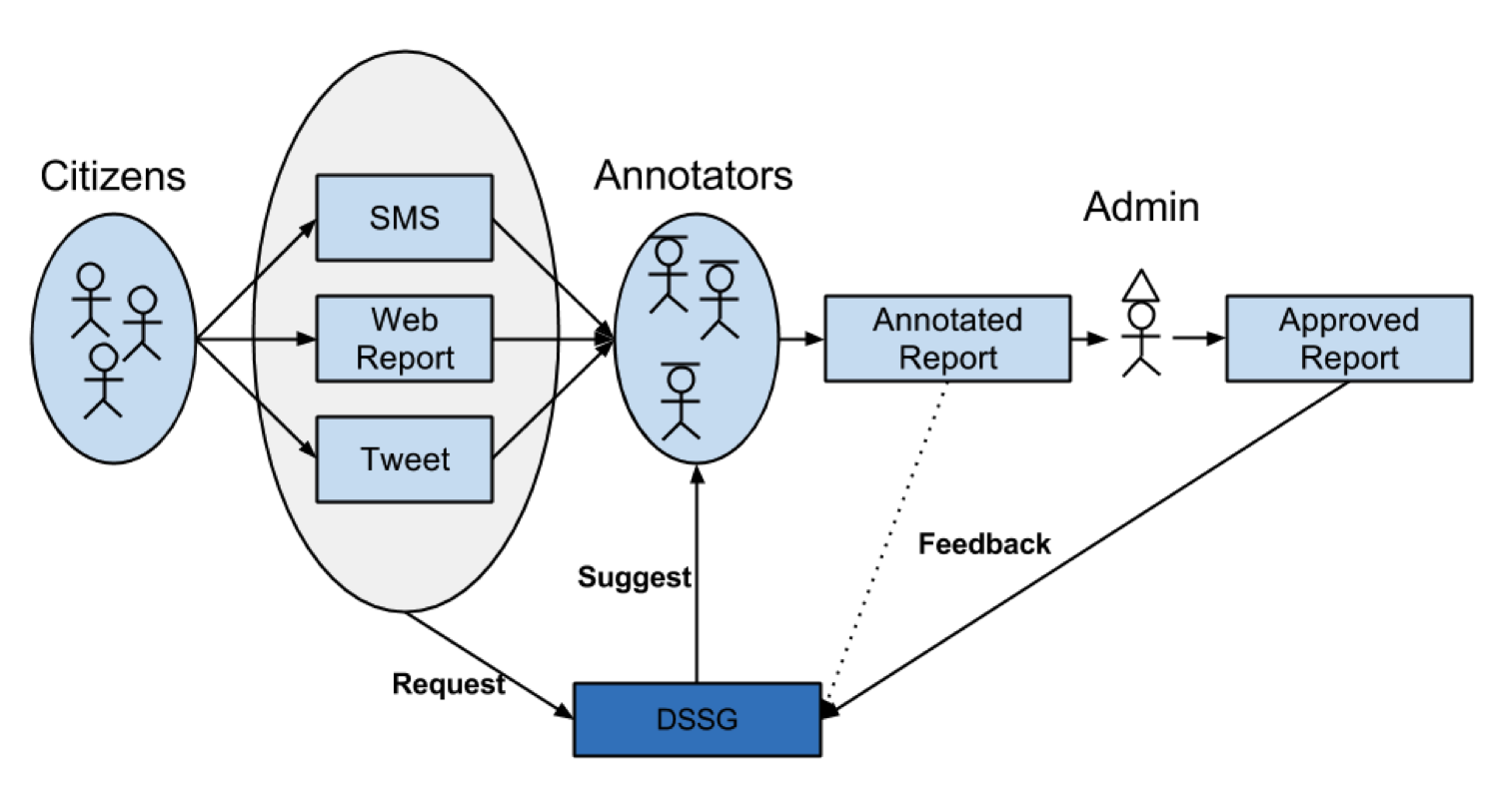
Instead of manually annotating each and every message during a crisis, the project team is developing a tool that will automatically suggest the languages, locations, and categories of incoming reports, allowing volunteers to concentrate on responding to the most urgent missives.
Before the Data, the Brainstorm
But there’s a catch: to build such a tool that can suggest category of a report, you need reports from past crises that Ushahidi’s volunteers have already categorized. As more human-labeled reports are fed into the tool’s classification algorithm, it gets better and better at categorizing them without human assistance. Without this historical “labeled data,” the algorithm can’t learn to categorize unlabeled text.
Because Ushahidi has been deployed all over the world, it took some time to gather reports from past crises.
So rather than digging immediately into the data, the Ushahidi team and their mentor Elena Eneva spent the first few weeks defining the problem: speaking with disaster relief experts, connecting with Ushahidi’s software engineers, and brainstorming the project. The team also observed a training simulation where Ushahidi volunteers practiced sorting crisis messages in real time, so that the fellows could identify how to improve the annotation workflow.
“We learned that how they assigned messages is very flexible: people in the chatroom saying they will take message number 10,” Leiby said. “So it sounds like that’s an area where if we can intelligently assign things to people, that might be helpful. We didn’t expect that at all.”
One idea inspired by that observation was to classify incoming messages by language, so that they could be automatically assigned to volunteers familiar with the language for further categorization. That became one of 20 brainstormed ideas the team pitched to Ushahidi, from which they chose four tasks that, if automated, would most help the volunteers in their sorting:
- detecting the language a Ushahidi report is written in, so it can be translated or evaluated by a native speaker
-
guessing a report’s category – such as “food” or “water” in the context of a natural disaster – so the map can be filtered
-
extracting locations from reports so they can be mapped
-
flagging (near) duplicate messages so they don’t clutter the map
The Value of a “Dumb” Prototype
Once the team received reports from 27 previous uses of the Ushahidi platform — including elections in India and Venezuela, floods in Pakistan, burglaries in Atlanta, and more – the team turned from user research to building a bare-bones prototype that sorts messages for those initial four tasks.
You simply plug in a tweet or SMS report, and the tool attempts to extract entities, detect language, suggest categories, and find similar messages:
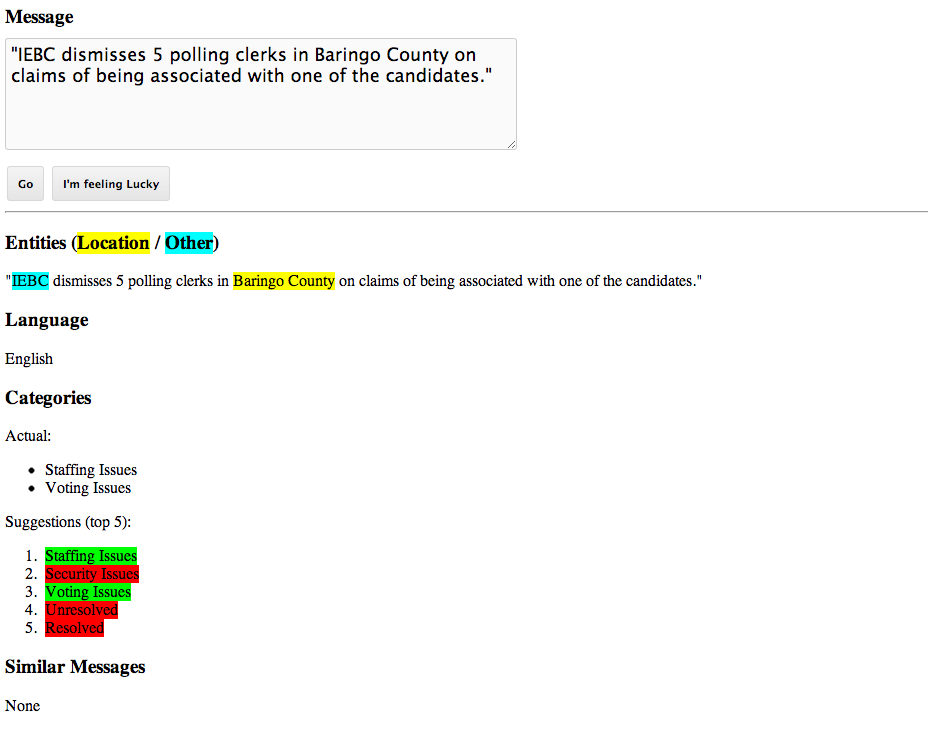
The team constructed this prototype using off-the-shelf machine learning tools for free text recognition and categorization. For automatic categorization of messages, the team is using scikit-learn, a Python machine learning library fellow Scott Alfeld introduced them to. The team is also working with the NLTK library to recognize entities and locations, and SimHash to detect duplicate messages.
The original prototype’s performance… well, it’s “not very good yet,” according to Jacobs, from Technion: Israel Institute of Technology. But this first iteration is a crucial first step towards the ultimate goal of the summer.
“That’s the very baseline proof that it’s possible,” Leiby said. “Then we can start to ask other questions: Is this the kind of information they would want? Can we give it to them in a more accurate or more prioritized form? How do we make it useful for you?”
Going forward, the team will flesh out the prototype, improving it iteratively as they get feedback from Ushahidi, Jun said.

Happily, the team found themselves with complementary talents that can be applied to these problems. While Kayla applies her background in natural language processing to the entity and duplicate recognition tasks, Kwang is using his machine learning experience to improve detection of categories and language, and Nathan is in charge of software framework setup and integration, as well as writing UI code.
“We’ve got three main sides to our project, which fits our team really well,” Jacobs said. “It’s been a real pleasure to work on this team, because we all have our own strengths and ways we can both teach each other and learn from each other.”