Empty and full stations pose a major problem in the Divvy system. After all, bike share really only needs two things to work: a bike to ride and a dock to leave the bike. Chicago’s commuting cycle (get it?) means that all the bike share bikes will end up under the butts of the workers who manage to leave their offices early.
Divvy, like other bike share programs in the US, has a solution: use trucks to rebalance the stations, carrying bikes from full racks to empty ones. The issue is that the trucks do the rebalancing reactively — waiting for a pile up before swooping in to save the day — rather than acting preventively.

To be more proactive, Divvy would need some mystic crystal ball that can see future bike share usage. The next best thing would be a statistical crystal ball, one that can guess with reasonable accuracy the number of bikes that are likely to be at a station in the future. That’s precisely what the DSSG Divvy team worked on last summer.

Meet the Poisson
When first thinking about how to solve the problem, we tried to compare the ways in which bikes move into and out of bike share stations to some familiar situations.
Fellow 1: “Predicting the number of bikes that arrives at a station is just like predicting the number of emails I get!”
Fellow 2: “I think it’s more like the number of traffic accidents that happen in Chicago!”
Fellow 3: “OMG it’s just like the number of Prussian soldiers kicked in the head by their horses in the mid-nineteenth century!”
As different as they sound, all three of these phenomena — receiving emails, getting into car accidents, or getting kicked in the head by your horse — are Poisson processes.
The basic intuition of a Poisson process is that the number of times a certain action will happen can be predicted using a rate. In any sort of prediction, however, there is some level of unpredictability. Instead of predicting the number of times something will happen, a Poisson process gives a distribution: a range of numbers with some weighted higher than others.
The graph below represents the expected number of emails I get in an hour. I tend to get about five, but there is always a certain amount of randomness. Sometimes I get three emails from food blogs and four from DSSG. Other times, I may only get two emails from family. The height of each bar represents the probability that I’ll receive that number of emails.
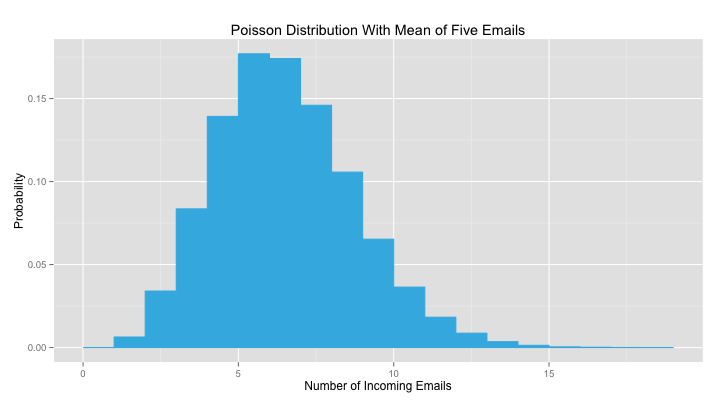
The rate of the process — the number of emails per hour — isn’t fixed. It may change over time due to any number of external factors. If you get more email at 10am (say, 23 emails an hour) than 3pm (5 per hour), the plot will look different at those times of day:
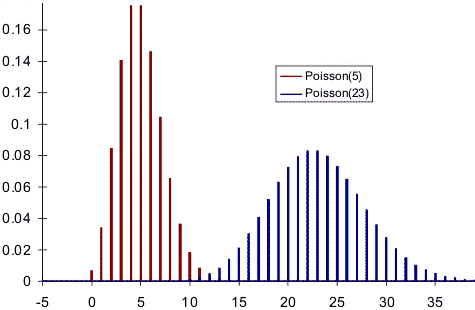
About 8% of the time, you’ll get exactly 23 emails between 10 and 11am (the blue bars). Most of the time, you’ll get between 18 and 28. It’s possible — but very rare — that you’ll get 5, even though that tends to happen 20% of the time at 3pm (the red bars).
The Poisson of Bike Share
In the case of bike share, these factors include time of day, weather, and the day of the week. As any driver can attest, weekday rush hour traffic and weekend midnight traffic are (literally) night-and-day, and bike share is no different. As one might expect, the number of bikes arriving, on average, is much higher during rush hour.
Temperature is also a big factor for bikers. A short commute in the early summer might feel endless when the temperature dips below twenty-five degrees. This chart shows that the average number of available bikes at a station in Washington DC (in this case, the station located at 14th & Rhode Island Ave) tends to shrink as the temperature goes up.
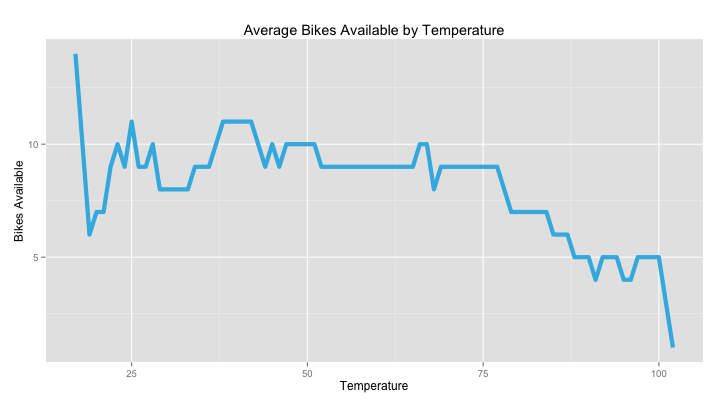
Once we’ve estimated the effect of time of day, temperature, and day of week on the rate of bike arrivals at a station, we can predict the expected change in the number of bikes at the station for every day of the year.
How (bikeshare) prediction works
By crunching lots of historical data, we can estimate the effect of time of day, temperature, and day of week on the rate of bike arrivals at a station.
For example, we might find that on average a downtown station gets 5 arrivals per hour. But this arrival rate is dependent upon external conditions:
- At 9am, in the middle of rush hour, there are 10 additional bikes coming in, or 15 arrivals per hour.
- There are fewer riders on weekends, so there are 2 fewer bikes arriving, or 3 arrivals per hour.
- Nobody likes the ride in the cold, so there 5 fewer arrivals in 50-degree weather, or 0 arrivals per hour.
Say it’s 9am right now. There are typically 15 arrivals an hour at the station (5 average arrivals + 10 due to the time of day). Since it’s a cold weekend, there are around 8 bikes ( -2 due to weekend – 5 due to cold weather ) – fewer than weekday rush hour on a nice summer day, but more than you’d see at 6pm when people are mostly departing from the station as they commute home.
That’s statistics in a nutshell: because we estimated the effect size of time of day and other factors, we can now predict the number of arrivals we are likely to see given specific inputs — 9am, weekend, and so on.
But we want to be able to predict the number of bikes at each station over the next hour or two, not the number of incoming bikes. The key is to build models for both arrivals and departures:
We start by fetching the number of bikes at every station in a city right now. Then we look at current conditions – say, it’s Monday, 10am in the morning, and its 78º F outside – plug these into our model, and predict the number of arrivals and departures we’re likely to see at every station over the next hour or two. We find the net change in bikes — 10 arrivals and 3 departures in the next 60 minutes means 7 additional bikes at the top of the hour — and add it to the current number of bikes to get our final prediction: there are 15 bikes at the station right now, so we’re likely see 22 there an hour from now.
Doing it for DC
Estimating the effect of all of the different factors (weather, weekend, time of day, etc) takes a lot of historical data, something that Chicago’s nascent bike share system doesn’t have yet. So we built our first round of predictive models for Capital Bike Share in Washington DC, a similar bike share system that has been around the block a few times — or a few hundred thousand times. DC’s system, introduced in 2010, has lived through all four seasons, several elections and many political scandals, so we can observe how stations behave under all sorts of conditions. Chicago’s station has only just made it through its first summer and fall.
Working with 18 months worth of data, we now have the ability to predict the number of bikes over the next two hours at each of the 246 stations in the DC’s bike share system.
Dispatchers are busy. They must simultaneously navigate the current state of the bike share system, the location of the trucks, city traffic and their own predictions of where the bikes are moving. While our models can help them with predictions, they don’t have the time to look through statistical output, p-values and confidence intervals. They need something simple that will help them do their job on the fly, something like a map of the predicted state of each station. Good news! That’s exactly what we made.
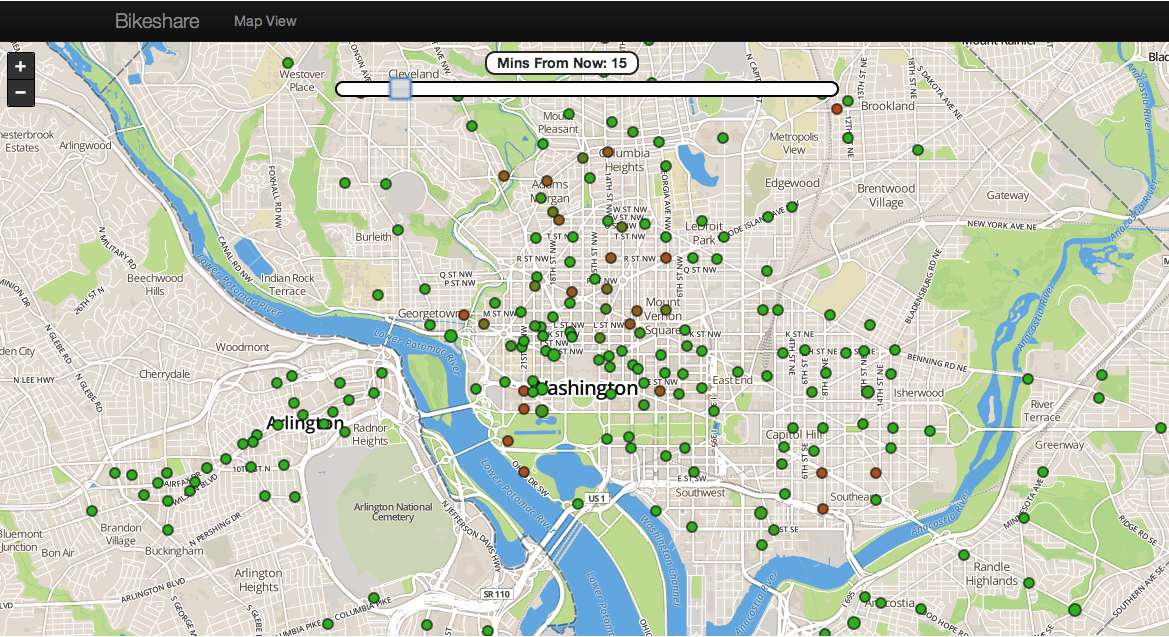
To start off, we can look at a station and it’s current number of bikes. The map has a slider that determines how far out we want to predict: fifteen minutes, thirty, forty-five, etc. up to two hours in the future.
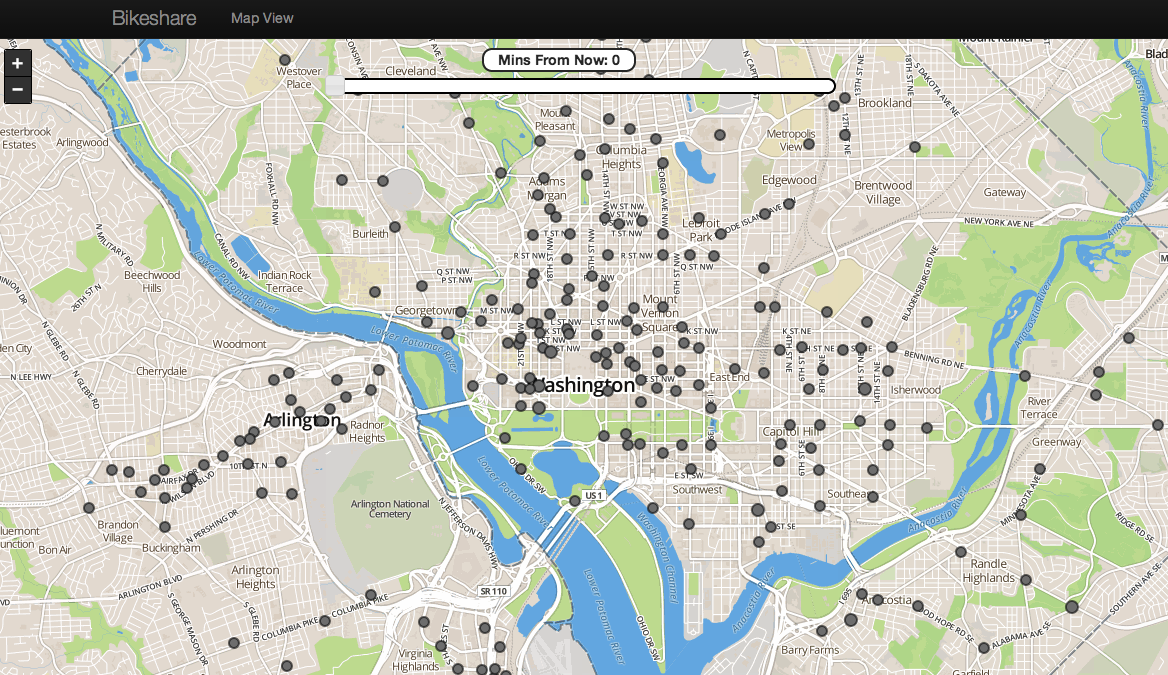
Move the slider and the colors of the circles change gradually between green and red. Green circles mean that will station likely be well-balanced and red circles mean “HEY! THIS STATION WILL PROBABLY BE EMPTY OR FULL, REBALANCE IT!”
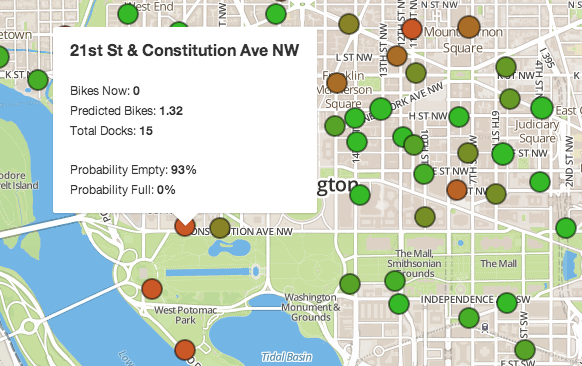
When a dispatcher wants to figure out where to move a bike, she can simply mouse over the stations colored red in order to see our predictions in detail. The window that pops up explains our predictions and gives a probability that a station will be empty in whatever amount of time she specified using the slider. The best place to move a bike would be into a station like the one shown below, where it is very likely to be empty.
Grading our predictions
Of course, a pretty map is only as useful as the information it supplies. Using historical data, we tested how well our predictions would have been if they were made in the past. As expected, predictions for fifteen minutes in the future are pretty great. Also as expected, predictions for sixty minutes in the future are not as hot.
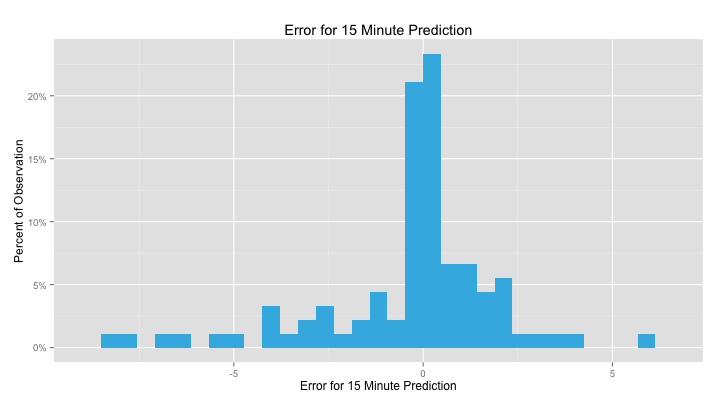
The station in the above graph is located at 16th & Harvard St in Washington DC and has 25 total bike slots. At fifteen minutes, over half of our predictions are within a single bike of the true number of bikes and over 90% are within five bikes.
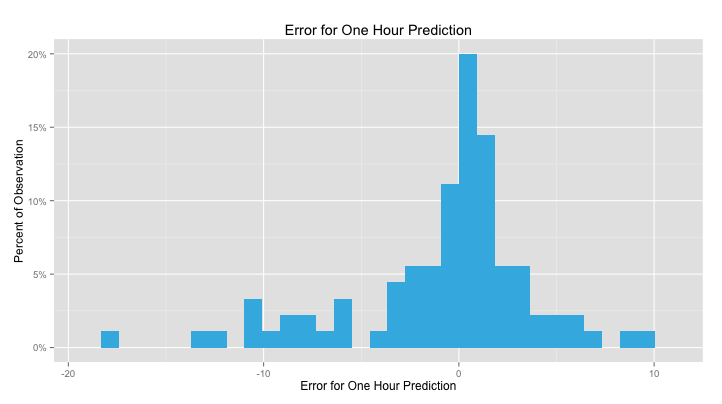
At sixty minutes, just over 30% of our predictions are within a single bike and only about 75% are even within five bikes. If, for example, we predict that there will be twenty bikes at the station in an hour, we can say with 75% certainty that there will be between 15 and 25 bikes. Those predictions are not very useful because 15 bikes means that the station is perfectly balanced and 25 means that it’s 100% full.
Though these predictions aren’t yet accurate enough to be used in the field, they’re a solid start. One way to improve them would be to make our existing models more complicated, factoring in the impact of things like CTA train arrivals, sports events and holidays on the arrival and departure rates of stations.
Another would be to start with totally different data: right now, we know the total number of available bikes and docks at each station every minute. We can tell bikes are arriving or departing, but not where they’re going to or coming from. Even though bikeshare is a network, this “heartbeat” data prevents us from modeling it like one.
If we had each bike’s daily trip data — the set of stations it departed from and arrived to (stripped of personal customer information, of course) — we could model the system holistically rather than treating each station as an island.
“How can I use it if there are no bikes?”
That was a pretty long-winded answer to a simple question – “How can I use it if there are no bikes?”
The short answer is that you can’t. No bikes means no bike share.
And that’s why rebalancing trucks exist. Once our predictions are up to snuff, they’ll be able to see which stations are likely to fill up, and move those bikes preemptively to stations that are likely to run out. No app can replace a real person’s knowledge of how the system works day-to-day, but ours can help re-balancers work more efficiently and bike sharing run (ride) more smoothly
To learn more about our project, visit our GitHub page.