Data-Driven Inspections for Safer Housing in San Jose, California

The Multiple Housing team in San Jose’s Code Enforcement Office is tasked with protecting the occupants of properties with three or more units, such as apartment buildings, fraternities, sororities, and hotels. They do so by conducting routine inspections of these properties, looking for everything from blight and pest infestations to faulty construction and fire hazards.
In June 2015, a balcony collapsed in Berkeley, killing six people and injuring seven more. Investigations found sub-standard construction and the accumulation of dry rot to be at fault, highlighting the importance of the work trained inspectors do to ensure problems are corrected before they result in disastrous consequences. Although the city of San Jose inspects all of the properties on its Multiple Housing roster, and expects to find minor violations at many of them, it is important that they can identify and mitigate dangerous situations early to prevent accidents.
Helping San Jose Prioritize Inspections
Our team is working with the City of San Jose’s Code Enforcement office to identify the multiple housing properties at highest risk of violations for more immediate and frequent inspections. With more than 4,500 multiple housing properties in San Jose — many of which comprise multiple buildings and hundreds of units — it is not possible for the city to inspect every unit every year. Some properties are less well-maintained and require more attention from inspectors than others, making prioritization of properties an important aspect of identifying violations in a timely fashion.
San Jose recently instituted a tiered approach to prioritizing inspections, inspecting riskier properties more frequently and thoroughly. The tier system provides an incentive structure as well: properties deemed to be riskier incur higher permit fees, but can move into a lower tier by cleaning up their inspection record or making proactive repairs.
However, the tier system has its limitations. First, tier assignments were based solely on how many inspections and violations a property had in the past, which leaves out a rich amount of information. Second, the city evaluates tier assignments for properties infrequently (every 3 to 6 years), and these adjustments require a great deal of expertise and manual work. We developed a predictive model to provide a more nuanced view of properties’ violation risk over time, allowing for more efficient scheduling of inspections.
Getting a View from the Ground

The San Jose Multiple Housing team assembles to talk about our work and the upcoming field trial
Close collaboration with partners is critical to the success of any project. We benefit greatly from spending some time face-to-face with the people behind the data and seeing firsthand how they will actually use our work. To that end, we recently spent a few days in San Jose, where we met with city staff and told them about our modeling process and field trial design, while soliciting their feedback on the results so far. We received several thoughtful suggestions for quirks to watch for in the data and additional predictors, such as shoddy repair materials, to consider in our future modeling.
We also rode along on Multiple Housing inspections, which provided an invaluable perspective on what inspectors look for when they visit a property, how their process is tracked and recorded (as well as what the data misses), and what the different service level tiers look like on the ground. We were surprised by the level of detail covered by inspectors, who noted everything from graffiti to the number of screws keeping water heaters in place. Insights like these – which can’t be learned from any amount of data exploration or “munging” – help us make sure our models find meaningful applications in the real world.
Modeling Properties At Risk for Violations
We use a combination of quantitative analysis and conversations with the people on the ground to decide how to balance the strengths and weaknesses of different models. Because we wanted our model to predict future outcomes, we chose an evaluation strategy called inter-temporal cross-validation.
The graphic below provides a simplified imaginary example of how this works with three three different models on how they performed against the actual results of inspections in 2014, 2015, and 2016. The models considered might differ in a number of ways, for instance: including or excluding different types of data, employing different modeling techniques, or focusing on more or less recent information. We start by building a set of models that seek to predict what will happen in 2014, using only information that would have been available to inspectors before January 1, 2014. We then evaluate the models based on what actually happened in 2014. Repeating this process for 2015 and 2016 gives us an idea of how well — and how dependably — a given model is able to predict the future.

A simplified example of our model evaluation process: three different models are trained using information prior to 2014, 2015, and 2016 and evaluated on what actually happened in those years. Looking at how each model performs over time allows us to balance stability and performance.
Which model would you choose? You can probably eliminate the yellow triangle model right off the bat. If we only looked at 2016, we’d choose the light blue squares model, but although it does well in 2016, it performed the worst in 2015, so we don’t know if we can trust its performance – what if it dips back down in 2017? Then again, what if 2015 was just some sort of anomaly? We don’t know the future (which is why we need analysis like this), but we want to give ourselves the best advantage we can. To balance consistency and performance, we choose a model that reliably performs well, even if it’s not always the best. Of course, in real life we were choosing between more than three models; we built and evaluated more than 100,000 models to arrive at the one we’re deploying in San Jose.
Throughout the project, we relied heavily on ongoing conversations with city staff. For example, these conversations helped us refine the scope of the project to focus on identifying the next 300 properties to inspect (approximately three months of work) and limit the violations we targeted to those likely to threaten the health and safety of residents. For instance, it wasn’t our priority to find houses that have lower level issues like cars parked in their front yards — we care more about issues like fire hazards and exposed wiring. Insights from the city also helped us find likely predictors, such as whether it has been a long time since a property’s owner has pulled a building permit.
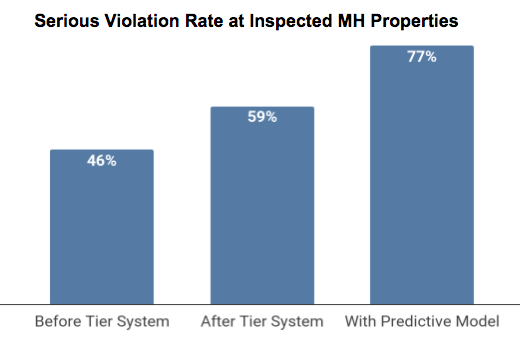
Comparison of the percent of inspections finding serious violations before the introduction of the tier system (2011-2014), after it was introduced (2016-present), and what our model evaluation suggests would have happened had it been in use (data from 2016-present).
To evaluate model performance, we consider precision, which is the proportion of violations within the top 300 properties suggested by the model. Delivering a model with high precision to San Jose means they will be able to focus their limited resources and inspectors’ time at properties where they are more likely to find violations. The multi-tier system has already helped focus their efforts: after it was introduced in 2015, 59% of properties inspected identified serious violations, compared to 46% in the three years prior (2011-2014). Looking at inspections from 2016 and early 2017, it appears that using the predictive model in conjunction with the tier system will help San Jose identify even more risky properties.
We also found factors that were particularly predictive of violations, many of which related to the property’s inspection and violation history:
- The amount of time since the last inspection at the property: Properties that have not been inspected in several years are especially likely to have violations present. This makes sense because if a property has had a recent inspection, they’re more likely to be aware of housing code and any existing issues.
- Presence of previous health and safety violations at the property: As the saying goes, past behavior is the best predictor of future behavior, and we saw that past violations were highly predictive. This probably reflects a number of factors, such as owners or property managers who are less invested in upkeep, or a property’s construction making it more prone to problems.
- Absence of recent building permits: More than 50% of properties with the highest predicted risk have no record of building permits in the past 5 years, compared to just under 30% of lower-risk properties. Our partners told us that every apartment building is going to need some updates within this time frame, so a lack of permits strongly suggests that there is either necessary work that hasn’t been done or unpermitted work that has been done.
- Violation rates at nearby properties: Properties in neighborhoods where recent inspections have found violations are more likely to have violations themselves, suggesting some communities within the city are more likely to feel the impact of these violations than others.
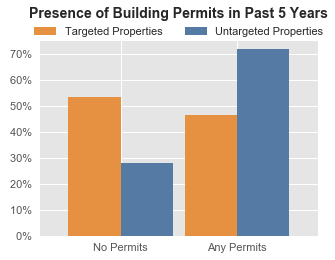

Distributions of two of the model’s important features: recent building permits and violation rates at nearby properties. In both graphs, orange bars represent properties the model suggests should be targeted for inspected in the next three months while blue bars represent all other properties. For instance, about 55% of model-targeted properties have not pulled a building permit in the last 5 years (compared to just under 30% of other properties), and about 90% of model-targeted properties are in areas where more than half of the inspections of nearby properties have found violations (compared to fewer than 60% of other properties).
Next Steps: Testing the Model
We’ve built a model on historical data; now it’s time to test it in the real world. Over the next few months, the city will be implementing a field evaluation to validate the effectiveness of the model, pitting model-based inspection prioritization head-to-head against the current strategy (which is based on tier and time since most recent inspection).
We identified the 400 properties with the highest modeled risk and the 400 properties that would be inspected in the absence of the model, yielding a combined set of about 600 properties (about 50% of the lists from the two strategies overlapped). Our field test, running through December 2017, will include inspections drawn from this combined set, providing data on what would happen both with and without the model. This way, we’ll see if the model can actually outperform the current system, and if we need to make any refinements before handing the model over to San Jose. The Multiple Housing team will also use insights from this work as they reevaluate tier assignments this fall.
This work is funded by the Laura and John Arnold Foundation through the Civic Analytics Network.