
Previously, we wrote about the problem facing Mexico and many other countries: maternal mortality. In 2000, Mexico joined many other UN countries in committing to reduce maternal mortality, making it a high priority initiative for its current administration. But over the past 10 years, the country’s maternal mortality rate has remained relatively stagnant despite the implementation of various initiatives like Seguro Popular and Oportunidades.
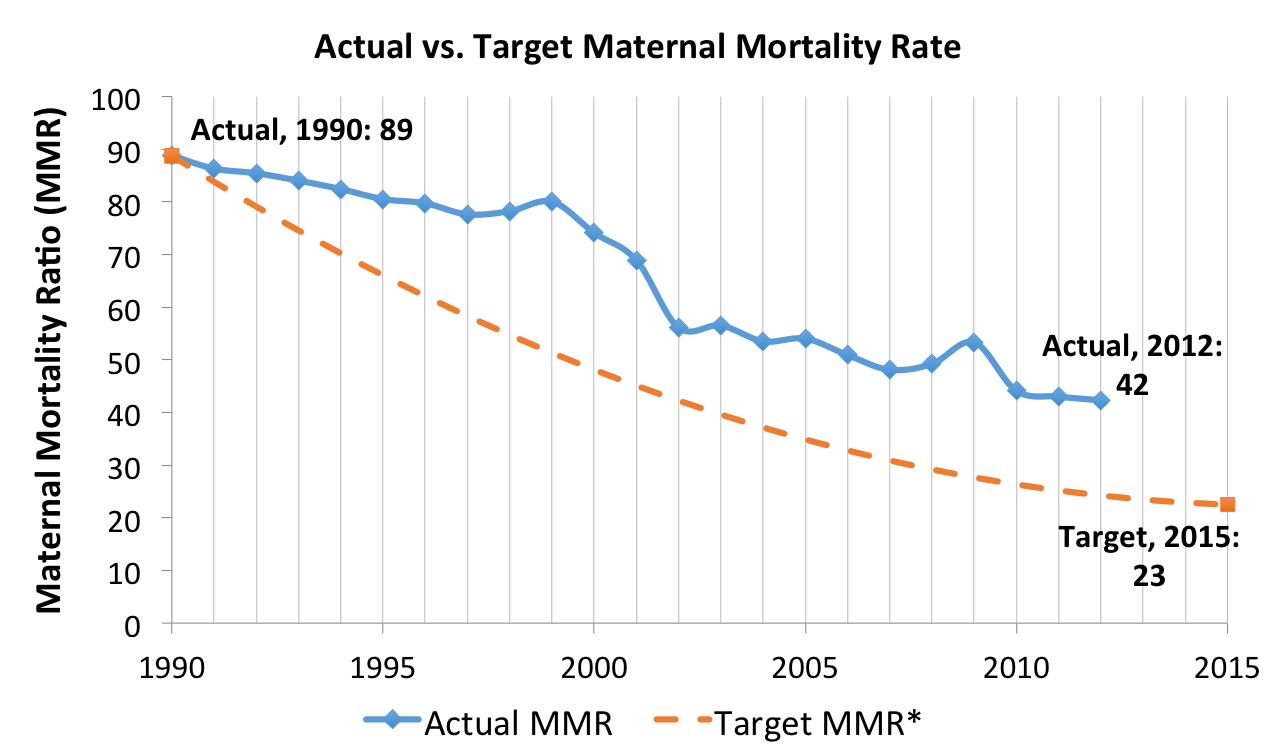
As a result Mexico asked our DSSG team to help design some new strategies for reducing maternal mortality. In this post, we’ll dive into our process for developing the recommendations we ultimately sent to Mexico, highlight some of the suggestions our work produced and how they will be used by our partners in Mexico’s Office of the President.
The Janitor Work
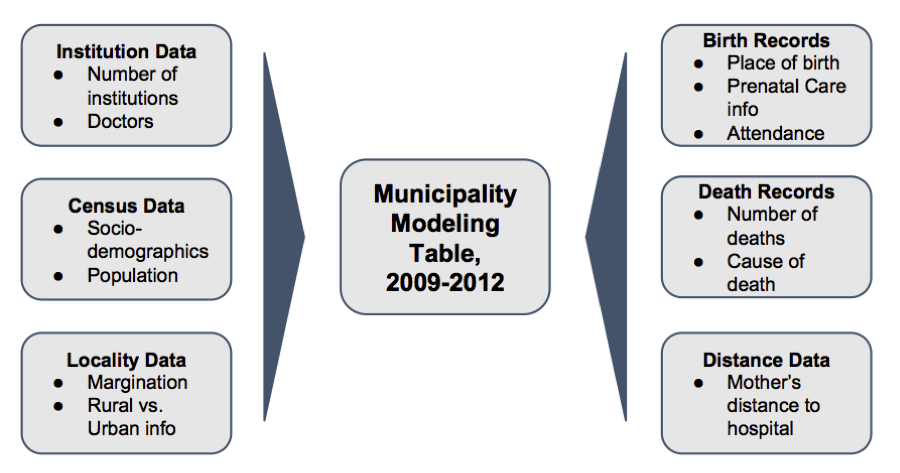
We were given a variety of data, including birth and death records, patient discharge records, hospital information, and census information, all going back to at least 1990. Great—we have a lot of information to work with. However, corralling all this info into something useful is always an interesting initial step for data scientists.
A New York Times article earlier this year described “janitor work” as the key hurdle to insights for data scientists. From our previous experiences working with data, we’ve definitely found that to be true. For Mexico, it wasn’t terrible, but there was still a significant amount of preliminary effort needed to get the data into usable form.
First of all, the data we received came in a variety of different formats: Microsoft Access databases, Excel files, and CSVs. In addition, we had a lot of files to work with—over 400 in total—so there was a bit of initial scripting involved just to convert and upload everything into a database. From there we needed to write additional scripts to clean the data of bad dates (according to the data, some people were close to 100 years old and having babies!) and differences in how variables were encoded between years. For the same database, a given value could mean something completely different across two different years, which could create big problems for any downstream analysis.
Just this initial step of setup was something of value to Mexico—it turned out that they had never created a single consolidated and cleaned data resource on maternal mortality.
The Right Level of Detail
After developing this database, we could then take a comprehensive look at the information, its strengths and weaknesses, and what we would be able to do with it. This process of diligence was referenced in our previous blog post, and mostly took the form of exploratory data analysis. We would come up with hypotheses, such as looking at the impact of different insurers on mortality rates, and then generate various cuts of the data to test them.
Our general approach to boil down all this data into something meaningful was to develop a statistical model that predicts maternal mortality, and subsequently examine the model and its variables to better understand the major factors contributing to or correlating with the outcome. In theory, such a model could tell us that a mother from a poor area is X times more likely to experience a maternal fatality than a mother from a wealthy area, or being poor is Y times more important than being uneducated. However, this level of detail would require an individual-level dataset of the mothers in Mexico, which the lack of any identifiers between our datasets made impossible.
So instead, we modified our initial approach to develop insights from a model of municipality-level death rates. Instead of using an individual mother’s attributes to determine her chance of survival, we would use the municipality’s attributes (such as what percent of the population spoke an indigenous language, or what percent had access to public goods, etc.) to model the mortality rates for mothers in that area.
Building The Pipeline
While great in theory, this approach posed a number of issues for us as well. For example, some rural municipalities could be very small, and over the four-year timeframe we were using for our data (when the mortality rate seemed most stable and unchanged by various implemented initiatives) might not have seen any maternal deaths. Therefore those municipalities looked like they had a great maternal death rate (0!), but in reality we knew that those areas were not risk-free. Also, in small municipalities, a single maternal death could spike the maternal mortality rate to huge levels since the population was so small and the number of births was so large.
So how do we make sure that these factors don’t throw our model for a loop? Do we only look at municipalities with a certain population size? Or those with at least one death? Should we not model the maternal mortality rate but a threshold—for example, whether a maternal death happened at all, or if the rate was above a certain value?
Furthermore, we arrived at other critical questions. Should we weight the model by a municipality’s population? Doing so would de-emphasize small municipalities where the problem was severe, but also be more representative of the country as a whole. Also, how should we deal with correlated variables, factors which are not independent but related in some way? These variables are trouble for some modeling techniques, and there are various ways to mitigate their adverse impact. With a multitude of directions to choose from, we decided to let data science figure it out for us.
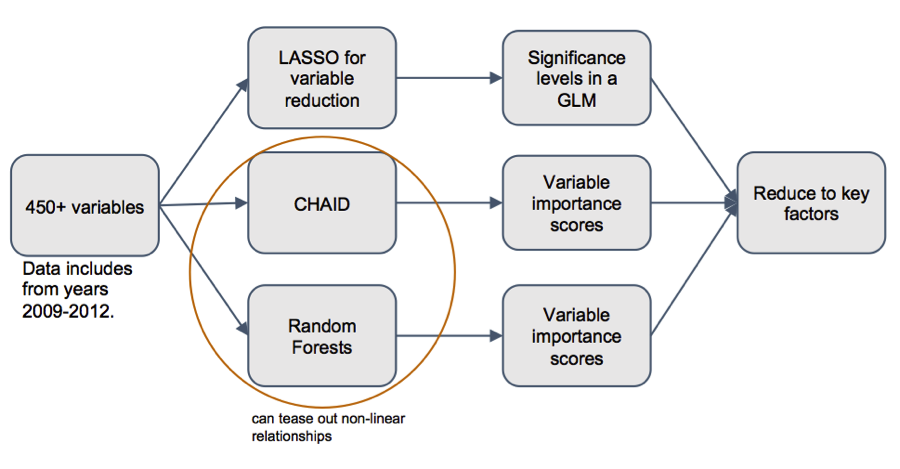
We developed a pipeline for our analyses that would run through all of the different variations and possibilities we came up with for our model and generate a report for each one. The pipeline would also try out different models on each variation, be it logistic regression, a decision tree, or a random forest, to see which fit the data best and if different variables were deemed important with different approaches. From there, we could look at the important variables coming out of each variation, which ones were consistent, which ones were not, and eventually develop a list of 5-10 key factors that we could explore further by hand to develop policy recommendations.
What The Data Recommends
We eventually came up with several recommendations for Mexico to reduce maternal mortality, mostly at the intersection of healthcare and poverty.
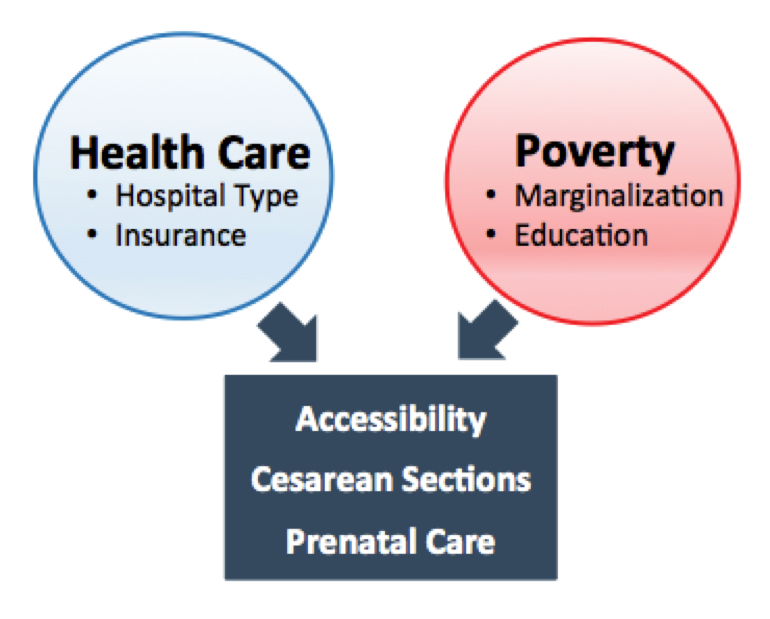
The most promising interventions our team suggested were: 1) increase prenatal care for marginalized populations, potentially through creating an incentive program to encourage prenatal visits, 2) investigate cesarean section cases in SSA hospitals, since much higher death rates were observed in these hospitals given the same population, and 3) investigate differential treatments in hospitals based on insurance type (as we detailed in our prior post).
For 1), we found that prenatal consults have a strong inverse relationship to maternal mortality, even after controlling for how impoverished a region was. Conditions related to lack of prenatal care, such as eclampsia, account for some of the most frequent causes of maternal death in Mexico indicating that increased prenatal visits and earlier time to care may mitigate some of the largest causes of death. We determined that incentivizing mothers to seek prenatal care early and frequently could have positive effects in reducing maternal mortality.
In fact, such incentive programs already exist for certain populations—mothers insured by IMSS receive maternity benefits only if they meet certain prenatal requirements. As a result, 15-20% more IMSS mothers receive prenatal care in their first trimester vs. a comparable Seguro Popular population (the other major health insurer), and they receive ~2 more prenatal visits during the course of their pregnancy. Such an incentive program would also have a much greater impact on highly impoverished populations who are ~30% less likely to receive prenatal care in their first trimester and receive ~2 fewer prenatal consults during a pregnancy, on average.
For 2) and 3), we found that, given the same population, mothers who give birth via cesarean section at SSA hospitals have a much higher death rate than those at Health Sector hospitals. Additionally, Seguro Popular mothers that attend Health Sector hospitals (and thus have an insurance mismatch) have much higher death rates than those with matching insurance, given the same population. While we could not determine an exact cause for these relationships from the data, we encouraged the Mexican government to further investigate these effects, as there may be operational changes that could reduce the number of these deaths.
Real Impact, Real People
One of our recommendations has already gained some traction. Our findings about the importance of prenatal care jump-started an initiative between Mexico and UNICEF to provide cell phones and send text messages to at-risk mothers encouraging them to seek prenatal care. In addition to increasing prenatal care via the program, Mexico hopes to also collect additional information about at-risk mothers, such as the timing and quality of their prenatal visits and identifying which mothers are most responsive to what types of interventions. This information will fuel further initiatives that will hopefully further reduce maternal mortality in the country.
This summer our team took on a truly interesting and impactful problem to help Mexico find new ways to reduce maternal mortality. For us, working on a problem with such a broad reach and significant goal was something we had never done before. It was all a bit of a whirlwind, as we not only needed to get quickly up to speed with the data but also with topics relating to maternal mortality in developing countries, especially in the context of Mexico. And fortunately, we were able to generate actionable results that have led to real initiatives! The Fellowship was an amazing experience where we did impactful work, learned a lot, and had a ton of fun doing it.