
Despite advances in prenatal and postnatal health care, maternal mortality remains a major medical problem around the world. According to the World Health Organization, 800 women die every day from preventable pregnancy and childbirth-related causes, with 99 percent of those deaths occurring in developing countries. In 1990, the United Nations made reducing maternal mortality by three-quarters one of its eight Millennium Development Goals (MDGs), and since then there are half as many such deaths around the world.
But some countries continue to struggle with maternal mortality. For their share of the MDGs, Mexico wants to reduce their Maternal Mortality Ratio (MMR, calculated by the WHO as # of deaths during pregnancy or within 42 days after birth , per 100,000 live births) to 22 by 2015. As of their latest estimate in 2012, they are currently at 42, around twice their target level. Our team – myself, Julius Adebayo, Eric Potash, Layla Pournajaf and mentor Ben Yuhas – are working with Mexico’s Office of the President and the Health Ministry of Mexico to identify unaddressed causes of maternal mortality and possible solutions to further reduce maternal deaths.
Mexico has come a long way since signing the Goals in 2000 – they’ve rolled out the Opportunidades program to encourage low income families to seek health care, they’ve given healthcare access to 52.6 million additional low-income individuals through their Seguro Popular program, and they’ve reduced their Maternal Mortality by 50 percent since 1990.
Despite those gains, their efforts still lag behind the ultimate goal. Over the past 10 years, Mexico’s MMR has stagnated despite additional efforts from the government to further bring it down. The chart below, adapted from a paper by Celia Hubert, shows the gap between the targeted MMR and the actual ratio since 1990, and the stagnation from 2002 to 2010.
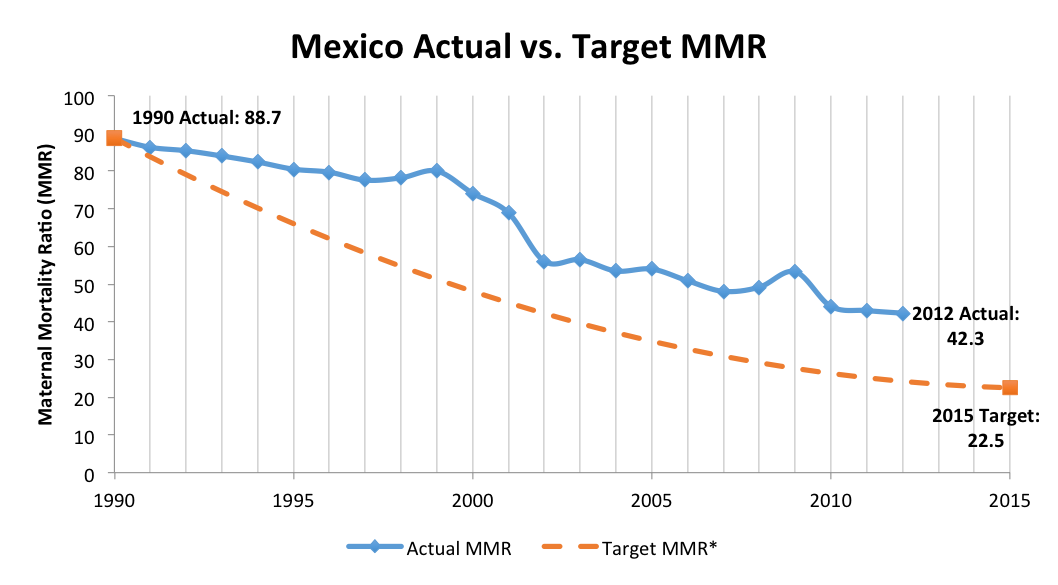
As a result, we’re working with the Office of the President of Mexico’s National Digital Strategy Office to scour their available data and better understand why their maternal mortality ratio has stayed relatively stagnant over the last 10 years. In addition, we’re also trying to understand maternal mortality at a level more granular than it has been studied before.
Information Overload
Prior evaluations and studies of the metric have primarily been at the state level. With the wealth of information we’ve been given, we’d like to study it at a municipality, or even a locality, level. There are 32 states (including the Federal District) in Mexico, whereas there are ~2,500 municipalities and over 192,000 localities. Understanding where there are issues at a level that’s potentially 6000 times more refined will enable Mexico to better target and design interventions for the sake of saving moms.
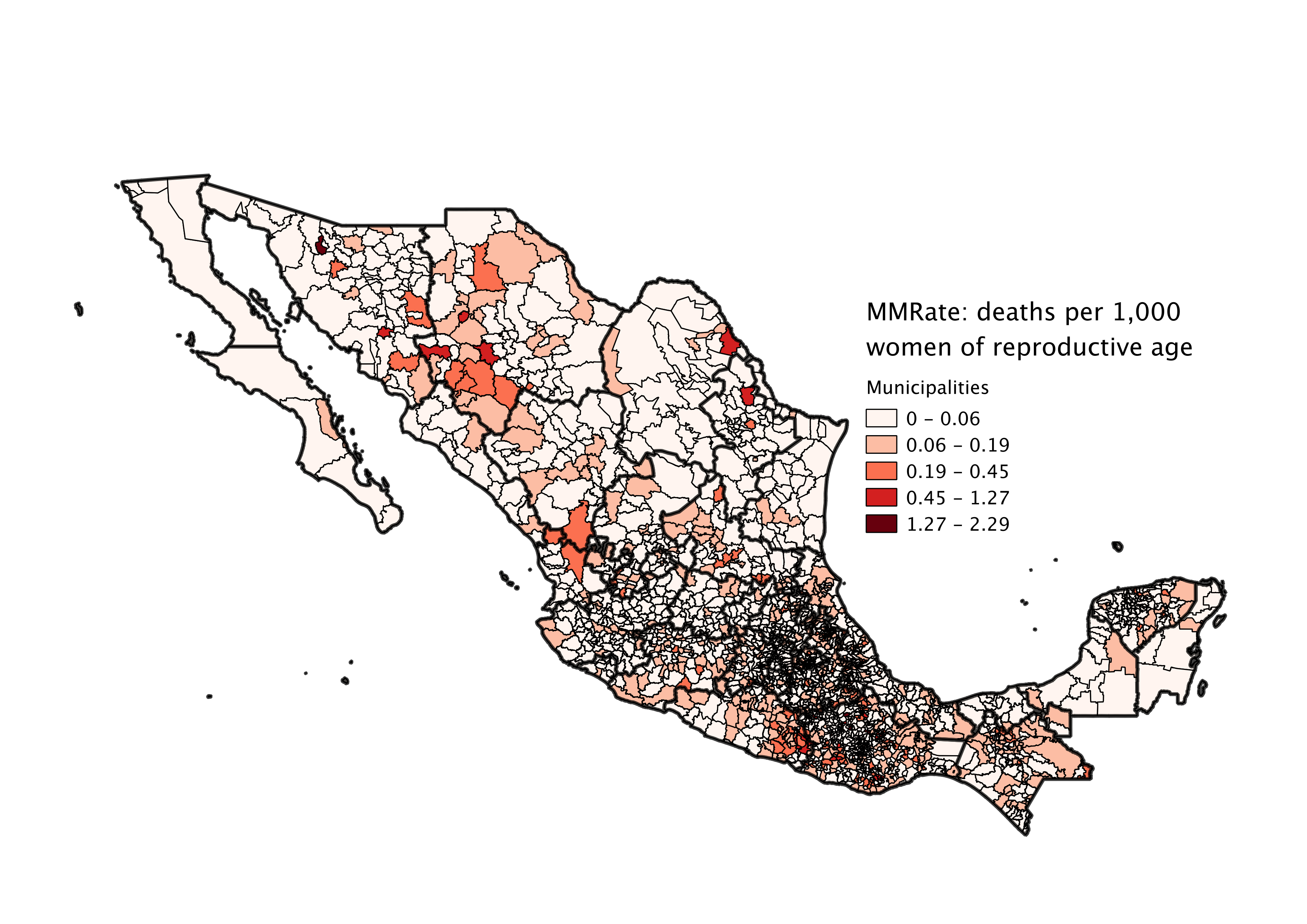
It’s actually quite amazing how much data has been collected on this issue. We’ve been given access to everything from census and hospital information, to birth records, death records, and even patient discharge records, anonymized and covering at least the past 10 years. Most challenging for us has been the variety of information present — we have so much data from different sources, we had a hard time figuring out where to begin.
Do we look at causes of death, the way different hospitals treat various types of visitors through examination of hospital data, or do we try to assess trends at a regional level from the census data? Although not a bad problem to have, the broad scope of our project and the vast avenues we could travel with the given information have sometimes left us overwhelmed with choices about where to go next.
Another interesting attribute about our data has been the fact that our datasets are disjointed and unlinkable. Whether it’s birth records, death records, hospitalization information, or regional information, each dataset comes from a different agency dealing with a specific aspect of our problem, and the anonymity of the data does not allow us to join records across datasets.
As such, we’re unable to combine the data in such a way that provides a single, holistic view of a mother, her journey through pregnancy, and whether she did or did not die as a result. Instead, we must analyze each aspect in a vacuum and piece together findings across datasets.
The lack of a longitudinal view constrains us from using certain machine learning or computational approaches. Many DSSG projects deal with predicting one type of outcome versus another — a classification problem. Classifier models can get complex and very accurate, but they come at the expense of interpretability.
In our project, interpretability for our models will be key, as our goal is not to predict but rather to understand the inner workings of the model to inform policy. This constraint actually makes our project more interesting, as we’re forced to take a more humanistic approach and assemble the Mexican maternal mortality puzzle using our own intuition.
The Role of Insurance
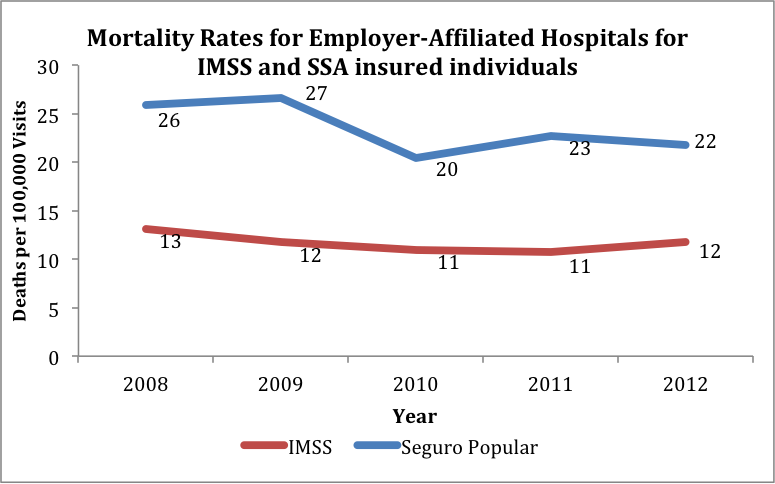
One interesting piece of the mortality puzzle we’ve been exploring has been insurance. In Mexico, most individuals either have insurance through their employer (e.g. IMSS for private employers) or the social safety net Seguro Popular. Furthermore, health institutions in Mexico are distinctly aligned with one form of insurance. Individuals with one insurer will rarely go to an institution with a different affiliation, unless necessary. If they do, and especially in the case of a Seguro Popular individual visiting an employer-affiliated institution, the mismatched individual will often be placed at the end of the triage queue.
The chart below shows the mortality rate for individuals visiting employer-affiliated institutions who have insurance either through IMSS or Seguro Popular. The graph distinctly shows a mortality rate for Seguro Popular individuals twice that of those with IMSS. It’s difficult to say the exact cause of this phenomenon — Seguro Popular individuals may be receiving poor treatment from employer-affiliated institutions and not being prioritized appropriately, or these individuals may be attending such an institution due to a dire need which places them in at higher risk in the first place. But it’s a clue to one area that the Mexican government may try to reform to improve their maternal mortality rates.
Finding the Right Risk Factors
Despite the situation with our data, we aren’t completely excluded from the machine learning fun. While we are unable to develop an individual longitudinal dataset for which to levy classification approaches, we can still seek to apply aggregate models at regional locality and municipality. In looking at factors such as socioeconomics, available facilities, access to facilities, urbanicity, and location, we will be utilizing various models to identify the highest risk regions and the key indicators of risk.
We will soon be leveraging decision trees, random forests, logistic regression models, Poisson regression models, and hierarchical models to various capacities in this regard. While we’re only in the preliminary stages of this phase, we’re excited about the insights the models may offer and are anxious to embark on this next step. We’ll be excited to share some exciting findings soon.